Metal是Apple提供的一套GPU框架,支持渲染和GPU的并行计算。用于组织,处理和提交图形和计算命令的细粒度,低级控制,以及这些命令的相关数据和资源的管理。
Metal采用命令模式框架,其中它抽象了几个概念:
Device:GPU硬件单元抽象,在iOS中使用MTLCreateSystemDefaultDevice()创建默认的GPU设备(Mac可能有多个GPU单元可以创建)。
CommandQueue:GPU运算队列,每个GPU单元对应一个运算队列(意味着iOS中只能创建一个),由Metal框架维护。
CommandBuffer:运算队列的基本执行单元,只有该单元提交(Commit/Enqueue)给GPU,才会开始真正利用GPU做运算。这个缓存区可以存储许多不同的编码命令,同时该缓存区是不可复用的它在提交给GPU后应该释放它。
CommandEncoder:命令编码器是一个运算的瞬间,它是我们执行渲染/计算的实体。
在Metal中支持并行运算,在这里我们可以从两个部分来实现GPU的并行。从下图可知,在Metal中Encoder和CommandBuffer这两个操作层级都是支持并行的。我们可以在多个线程中提交编码命令缓冲区(CommandBuffer)和命令编码器(CommandEncoder)。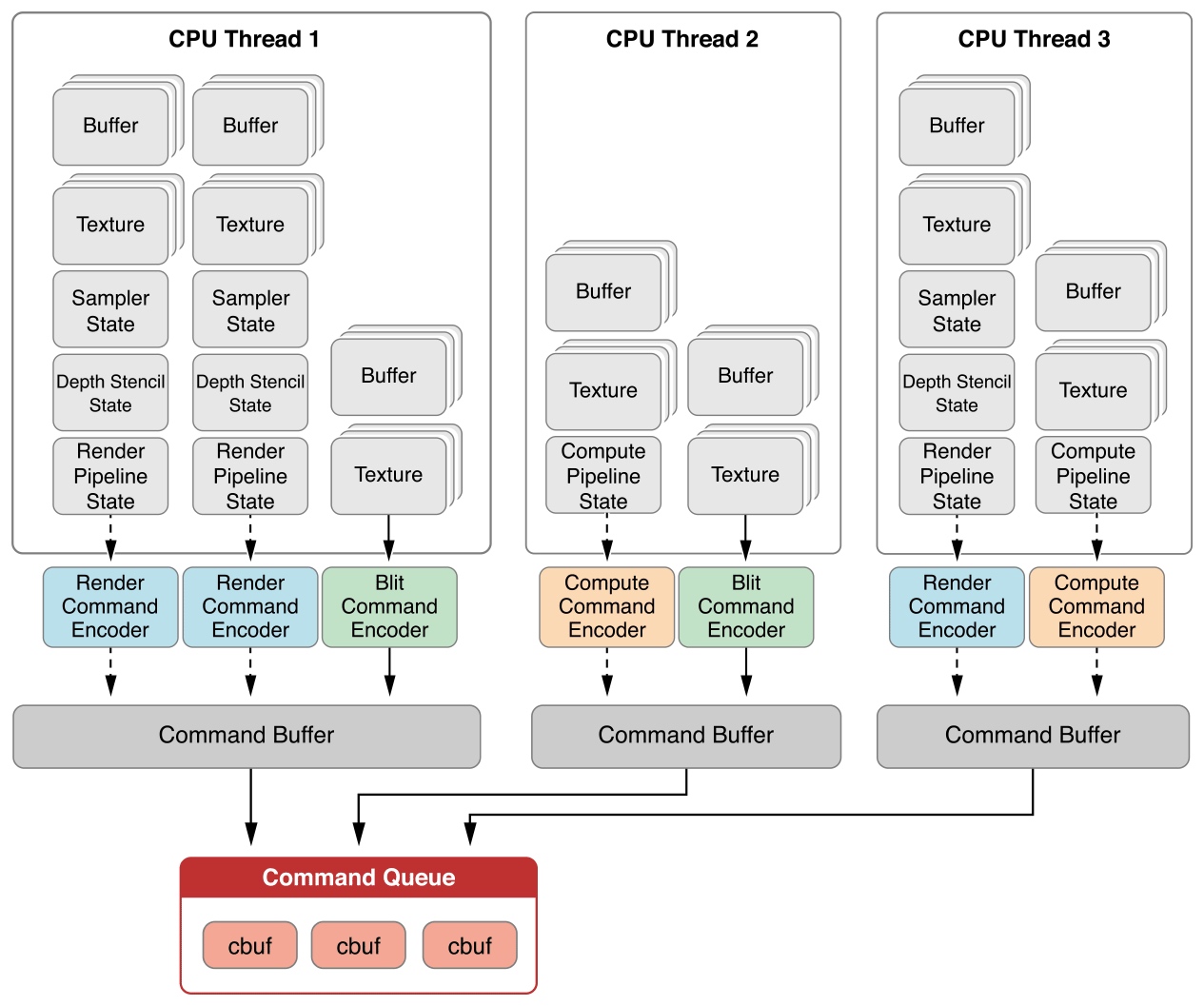
使用Metal主要有几个好处:
- 高层次的硬件图像处理抽象。
- 支持多线程,资源管理。
- 原生的GPU/CPU性能优化(相较于OpenlGL)
- 非常方便的调试。
Metal资源管理
在Metal框架中主要以协议拓展的形式来抽象各个类。同时整套Metal框架中的对象都抽象到OC层所以我们使用原生的内存管理方式(MRC/ARC),我们常用到对象和它们的生命期如下图:
MTLLibary:指的是Metal Shader仓库,它在App编译的时候就被创建了。
MTLDevice:是GPU硬件资源的抽象,在iOS平台上只有一个默认的设备而Mac上可能有多个GPU核心,在App初始化的时候被创建。
MTLCommandQueue:每个MTLDevice有且只有一个命令队列,它应该只被创建一次。
MTLRenderPipelineState:在Metal框架中渲染管线这个概念的抽象(同OpenGL),它表示了一次完整的绘制流程,可包括多个Draw-Call。
MTLComputePipelineState:在Metal框架中不仅支持渲染,还支持高并发的GPU计算,它表示一次完整的计算流程。
MTLTexture:在Metal中纹理概念的抽象。
MTLBuffer:一般在这个通用的Buffer容器中存储我们向Shader传入的数据。
Metal中的瞬态和非瞬态对象
Metal中的一些对象设计为瞬态且极轻量级,而其他对象则更昂贵且可能持续很长时间,可能是应用程序的生命周期。
命令缓冲区和命令编码器对象是瞬态的,仅供单次使用。
- CommandBuffer
- CommandEncoder
以下对象不是瞬态的。在性能敏感的代码中重用这些对象,并避免重复创建它们。
- Command queues
- Data buffers
- Textures
- Sampler states
- Libraries
- Compute states
- Render pipeline states
- Depth/stencil states
渲染流程
文章顶部的那张图已经概括了Metal框架的处理流程和处理粒度。首先我们从CommandQueue中取出一个命令缓冲区(CommandBuffer),然后编写数个同步或异步的渲染命令编码器(RenderEncoder)完成渲染操作。
[CommandQueue commandBuffer] -> RenderEncoder -> Draw-Call…Draw-Call…Draw-Call -> [RenderEncoder endEncoding] -> [CommandBuffer Commit]
以下是官网上的示例代码,这里MTLRenderPassDescriptor这个概念需要值得注意。它表示渲染流程中的背景描述信息,它里面有一个colorAttachments数组表示绘制画布的一些基本信息(包括设置当次绘制的背景色/目标纹理/存储方式等)。
也就是我们在当次渲染的结果会存储到MTLRenderPassDescriptor中挂载的目标纹理。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38- (void)render:(MTKView *)view {
// Update your dynamic data
[self update];
// Create a new command buffer
id <MTLCommandBuffer> commandBuffer = [_commandQueue commandBuffer];
// BEGIN encoding any off-screen render passes
/* ... */
// END encoding any off-screen render passes
// BEGIN encoding your on-screen render pass
// Acquire a render pass descriptor generated from the drawable's texture
// 'currentRenderPassDescriptor' implicitly acquires the drawable
MTLRenderPassDescriptor* renderPassDescriptor = view.currentRenderPassDescriptor;
// If there's a valid render pass descriptor, use it to render into the current drawable
if(renderPassDescriptor != nil) {
id<MTLRenderCommandEncoder> renderCommandEncoder = [commandBuffer renderCommandEncoderWithDescriptor:renderPassDescriptor];
/* Set render state and resources */
/* Issue draw calls */
[renderCommandEncoder endEncoding];
// END encoding your on-screen render pass
// Register the drawable presentation
[commandBuffer presentDrawable:view.currentDrawable];
}
/* Register optional callbacks */
// Finalize the CPU work and commit the command buffer to the GPU
[commandBuffer commit];
}
- (void)drawInMTKView:(MTKView *)view {
@autoreleasepool {
[self render:view];
}
}
数据缓冲更新
Metal框架是支持并发处理的,所以我们在更新数据缓冲区的时候可以使用信号量机制去控制资源的同步。下面是两个典型的数据更新场景:
单个数据缓冲复用更新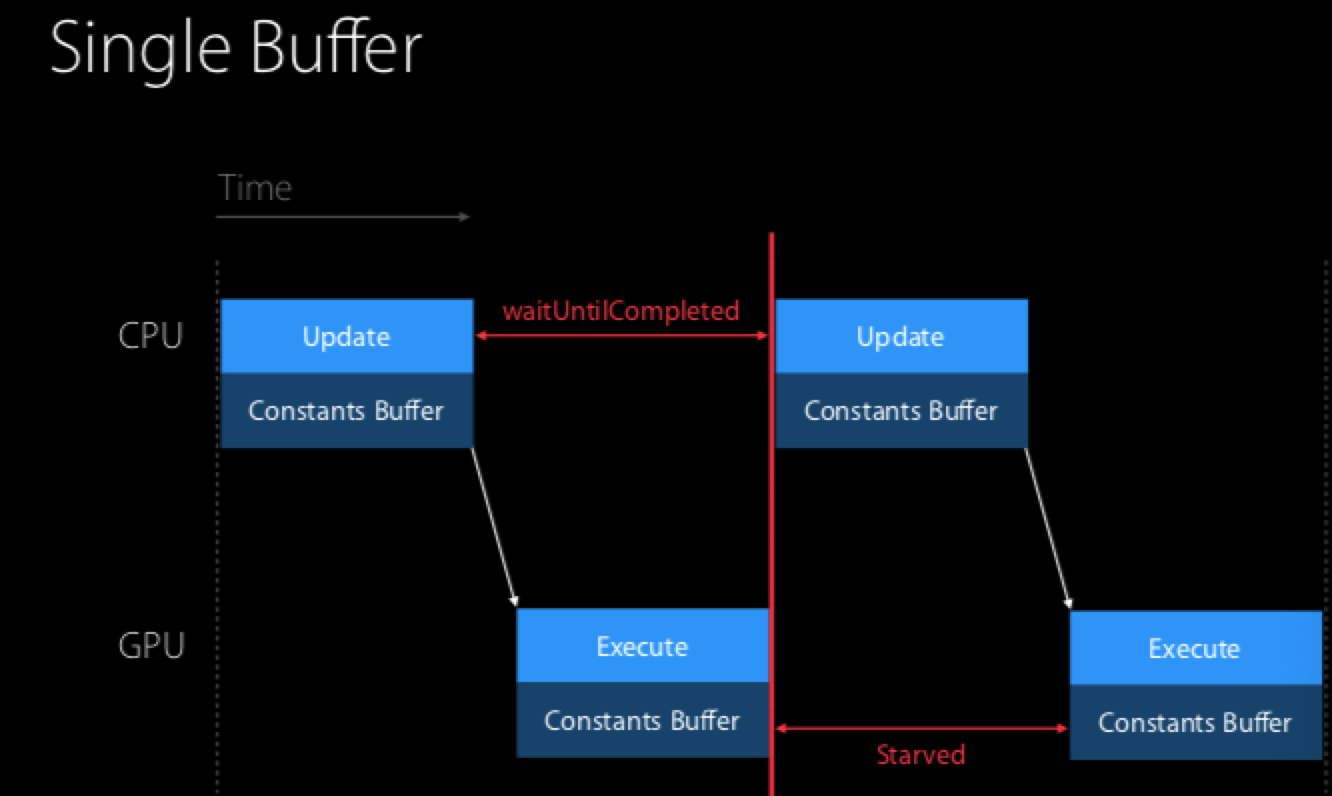
三级数据缓冲更新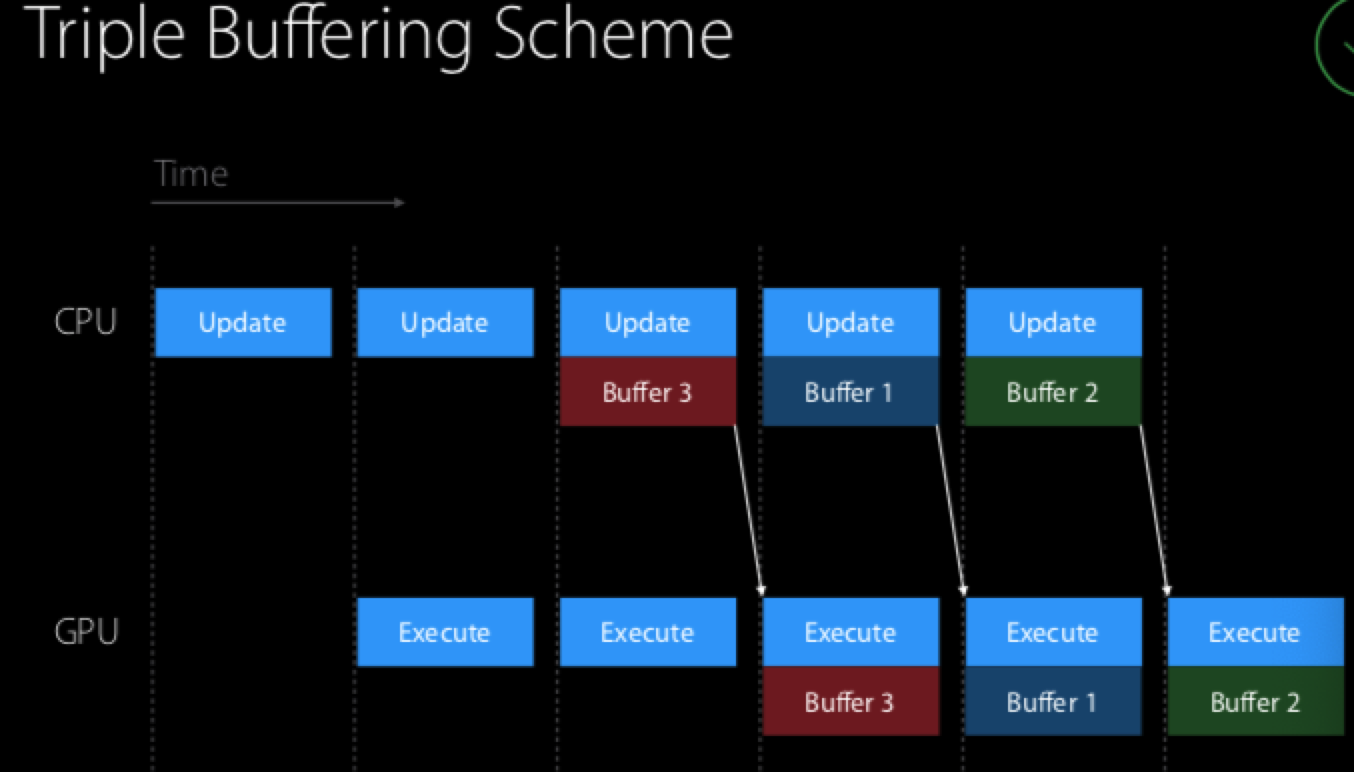
1 | - (void)render { |
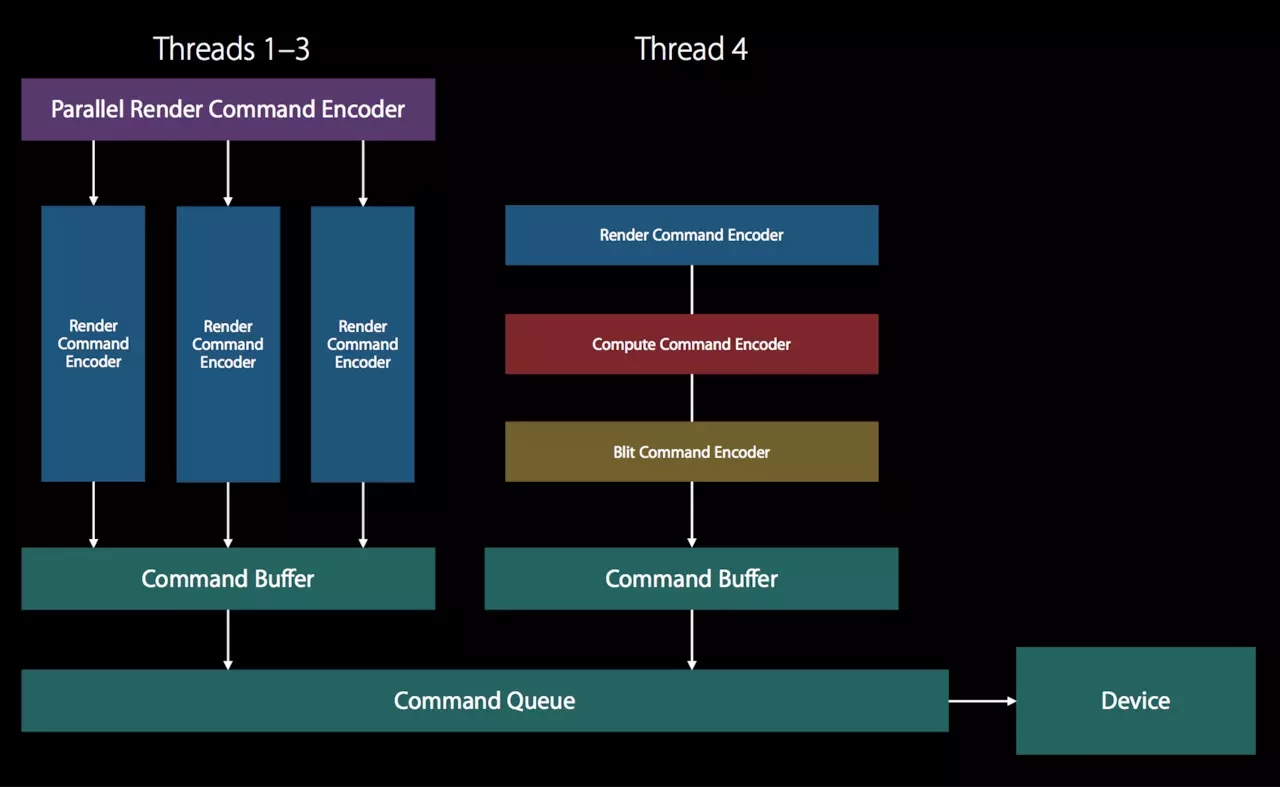
并发的RenderEncoder
Metal在Encoder层级也可以实现并发处理操作,意味着我们可以在同一个RenderEncoder实现多个Draw-Call的并行处理。
1 | MTLRenderPassDescriptor *renderPassDesc |
总结
相较于OpenGL的API,Metal的API显然对开发者友好了许多。我们可以很方便的利用其GPU的性能,这里有一个参考GPUImage设计的一个Metal图像处理框架